음성에서 개인정보 숫자열을, 텍스트로 옮기지 않고 잡아낼 수 있을까
기존 방식은 음성을 먼저 STT로 텍스트화한 뒤, 그 텍스트에서 개인정보 숫자열 패턴을 찾는 구조입니다.
하지만 이 과정에서는 개인정보가 텍스트로 남을 수 있고, STT가 숫자를 잘못 전사하면 탐지 결과도 함께 흔들립니다.
그래서 우리는 질문을 바꿨습니다.
“텍스트로 옮기지 않고, 음성 신호만으로 개인정보 숫자열을 잡아낼 수 있을까?”
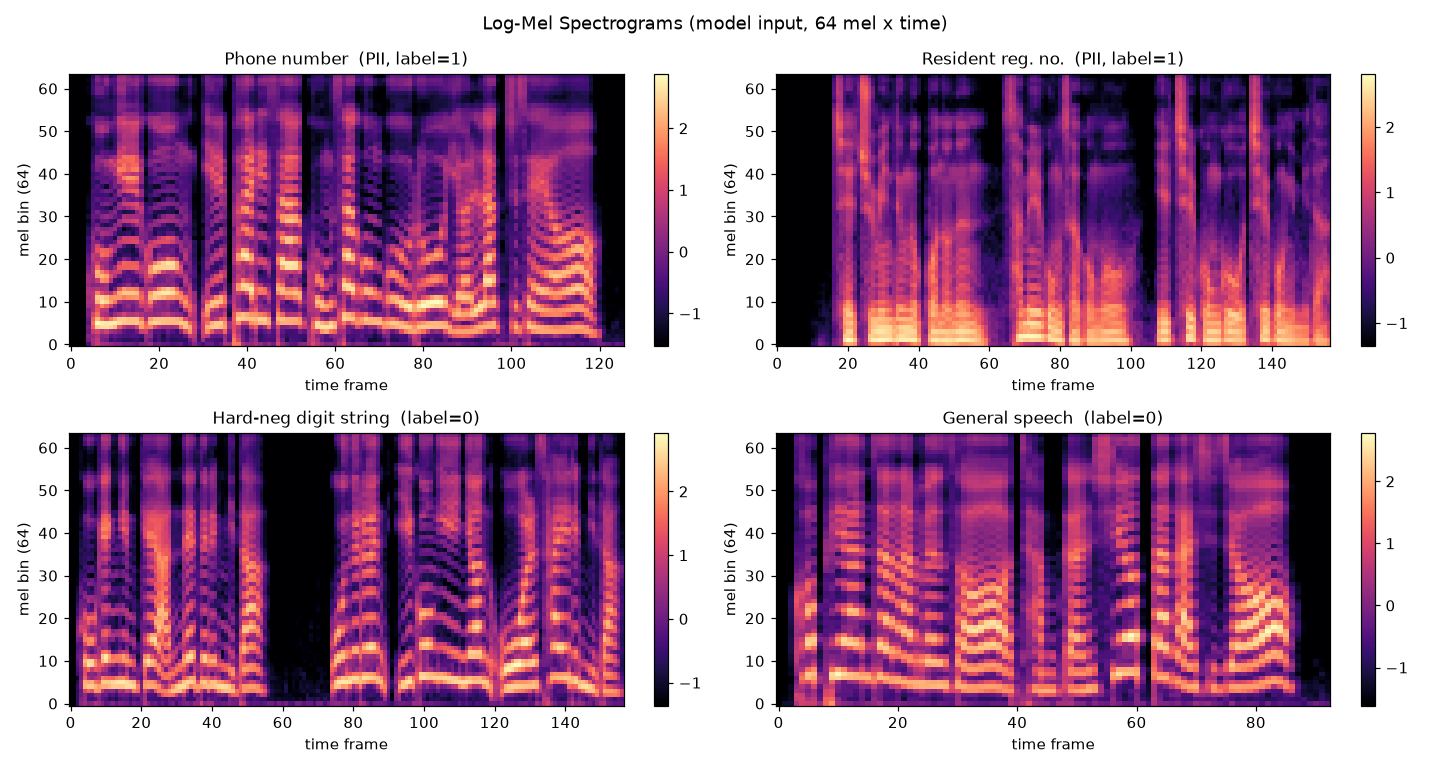
본 프로젝트는 음성을 log-mel 스펙트로그램으로 변환한 뒤, 60.7K 파라미터의 경량 CNN으로 PII 숫자열 포함 여부를 분류하는 접근을 실험적으로 검증했습니다.
1문제 정의 — 왜 STT를 우회하려 했는가
기존 음성 개인정보 탐지는 보통 전체 음성을 STT로 텍스트화한 뒤, 텍스트 NLP나 정규식으로 숫자열 형식을 판별하는 구조입니다.
하지만 모든 음성을 대형 STT로 전사하면 비용과 지연이 커지고, 개인정보가 포함될 수 있는 음성을 텍스트로 남긴다는 점 자체가 프라이버시 부담이 됩니다.
그래서 본 실험은 STT를 대체하는 것이 아니라, STT 이전 단계에서 동작하는 초경량 PII 후보 선별기를 목표로 했습니다.
핵심 질문은 다음과 같습니다.
“정밀 전사를 수행하기 전에, 이 클립에 PII 숫자열이 들어 있을 가능성만 먼저 빠르게 판단할 수 있을까?”
이 앞단 선별기의 핵심 지표는 정밀도보다 재현율과 연산 효율입니다. 정확한 형식 판별은 뒤로 미루고, 여기서는 위험 클립을 놓치지 않고 빠르게 걸러내는 데 집중합니다.
2가설 — 음향적으로 다른 연속 숫자열
본 실험의 가설은 단순합니다.
전화번호·주민번호·계좌번호·카드번호처럼 개인정보로 쓰이는 숫자열은 대체로 여러 자리 숫자가 연속해서 발화됩니다. 이때 일반 문장 발화와는 다른 반복적 리듬, 짧은 음절 단위의 나열, 비교적 일정한 발화 간격이 나타날 수 있습니다.
즉, 모델이 잡으려는 것은 개인정보의 의미가 아니라 연속 숫자열이 만들어내는 음향적 패턴입니다.
음성을 log-mel 스펙트로그램으로 변환하면 이러한 시간-주파수 구조가 이미지 형태로 표현됩니다. 따라서 텍스트 전사를 거치지 않더라도, CNN이 일반 발화와 긴 숫자열 발화 사이의 패턴 차이를 학습할 수 있다고 보았습니다.
3접근 — log-mel 스펙트로그램 + 경량 CNN
음성을 16kHz로 받아 log-mel 스펙트로그램(n_fft=1024, hop=512, n_mels=64)으로 변환하고, 4단의 Conv-BN-ReLU-MaxPool과 AdaptiveAvgPool을 거쳐 이진 분류합니다. 평가 시에는 슬라이딩 윈도우로 자른 뒤 각 윈도우 확률의 최댓값을 클립 점수로 삼아, 일부 구간에만 PII가 있어도 놓치지 않도록 설계했습니다.
4실험 여정
단발성 실험이 아닌 5단계의 실험